영형 데이터를 범위로 그룹화 를 얻는 데 사용됩니다. 주파수 분포 연속 데이터 세트 또는 많은 관찰이 있는 경우, 개별 값인 경우에도 마찬가지입니다.
더보기
리우데자네이루에서 온 학생들이 올림픽에서 메달을 놓고 경쟁합니다…
수학 연구소는 올림픽 등록을 위해 열려 있습니다…
~에서 데이터 분석 학술 및 기업 환경에서 중요한 의사 결정을 위한 정보 추출 및 통찰력 확보가 가능합니다.
그러나 원시 데이터는 변수의 동작에 대해 거의 또는 전혀 말하지 않으므로 다음과 같은 데이터를 구성하고 요약하는 기술을 사용해야 합니다. 주파수 분포.
값이 데이터 세트에 나타나는 횟수를 계산할 때 절대 주파수.
변수의 가능한 각 값의 빈도를 계산하여 빈도 분포를 얻습니다.
절대 빈도를 총 관측 수로 나누면 다음을 얻을 수도 있습니다. 상대 빈도.
예:
회사 직원 자녀 수의 빈도 분포.
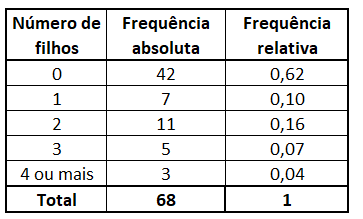
데이터 세트에 많은 관측값이 있거나 데이터가 연속적이면 간격으로 그룹화해야 하며 클래스라고도 하는 각 간격에 대한 빈도를 얻습니다.
데이터 그룹화를 가져오는 단계를 참조하세요.
1단계) 클래스 수를 정의합니다.
클래스 수에 대한 규칙은 없습니다.
그러나 많은 클래스를 고려하면 데이터가 요약되지 않고 매우 큰 테이블이 됩니다. 반면에 소수의 클래스만 고려하면 데이터에 대한 정보가 손실되고 테이블이 매우 줄어들게 됩니다.
따라서 이상적인 것은 데이터의 특성과 데이터에 대한 지식을 기반으로 클래스 수를 결정하는 것입니다.
2단계) 클래스의 범위를 계산합니다.
클래스 범위를 계산하려면 클래스 수와 전체 범위가 필요합니다.
즉:
3단계) 컴퓨팅 클래스 제한.
클래스는 하한(Li)과 상한(Ls)으로 구성되며 다음과 같이 표현할 수 있습니다.
이는 구간에 Li보다 크거나 같고 Ls보다 작은 값이 포함되어 있음을 나타냅니다. 즉, 구간 [Li, Ls)입니다.
첫 번째 클래스는 가장 작은 데이터 값인 Li로 시작합니다. L을 얻기 위해 클래스 범위에 Li를 추가합니다.
Li를 이전 클래스의 Ls 값으로 간주하여 다른 클래스도 비슷한 방식으로 구합니다.
예:
오름차순으로 25명의 체육 학생의 키(cm)를 고려하십시오.
159 160 164 168 169 169 169 170 172 172 173 175 175 175 177 179 180 182 182 184 186 186 188 190 192
5개의 클래스를 살펴보겠습니다.
첫번째 교시:
Li = 159 및 Ls = 159 + 6.6 = 165.6
이급:
Li = 165.6 및 Ls = 165.6 + 6.6 = 172.2
병종:
Li = 172.2 및 Ls = 172.2 + 6.6 = 178.8
4등석:
Li = 178.8 및 Ls = 178.8 + 6.6 = 185.4
다섯 번째 클래스:
Li = 185.4 및 Ls = 185.4 + 6.6 = 192
25명의 체육 학생 키의 빈도 분포:
| 신장 등급(cm) | 절대 주파수 | 상대 빈도 |
| 3 | 0,12 | |
| 7 | 0,28 | |
| 5 | 0,2 | |
| 5 | 0,2 | |
| 5 | 0,2 | |
| 총 | 25 | 1 |
참고: 마지막 클래스에서 상한은 클래스에 속합니다.
당신은 또한 관심이있을 수 있습니다:
